

Activation Energy
Breaking down the compounding potential of matter industries

Welcome back to Techpolitik - thanks for being here.
Last month I wrote about learning curves, and since then i’ve had a bunch of conversations with founders and investors about why deep tech suddenly feels like it’s speeding up. This is my attempt to explain it - in short, the cost of “finding out” is collapsing... Hope you enjoy it and please reach out if you want to talk more about this, deep tech or anything else!
Jonno

2026 marks the moment where the cost to test an idea collapses faster than the cost to generate one, and that changes everything about how we build companies.
For decades, innovation meant careful, expensive bets. You had one shot at designing a molecule, building a prototype, or running a trial. Testing was prohibitively expensive, so you optimised for being right the first time.
That world has ended.
Across biology, materials, energy, manufacturing and beyond, the cost to find out is falling. Physics simulation has improved, robots run labs and factories, and compute and sensors are better and cheaper than ever. When testing becomes cheap enough, innovation stops being about making careful bets and more about searching aggressively through possibility space.
That shift can be captured by a simple model.
Innovation as search
A clean way to express the whole story is:
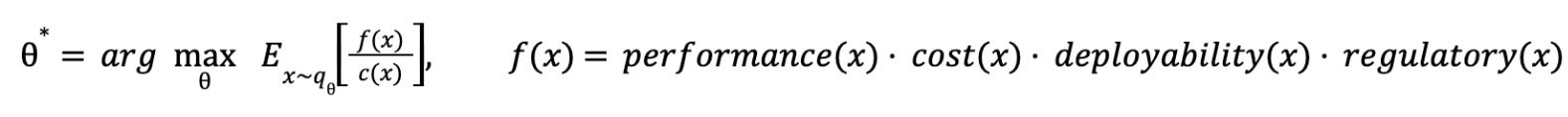
It looks technical, but it is just a precise description of what every lab, factory, and product team does: generate a candidate, test it, learn whether it is good, pay for it, repeat.
Start with x. A candidate design x is one specific attempt: this molecule, this factory layout, this power topology, this clinical protocol. You can hold x in your head as “this particular idea”.
Now f(x). That is the true score of x, but it is latent. You do not get to read it off a slide deck. You only learn it after you test. In the real world f(x) is not one thing, it is a bundle. Does it work, can we build it profitably, can we deploy it at scale, and will it survive regulation. The multiplication is a blunt but useful reminder that weak links kill projects. A drug that works but cannot be approved is not “half valuable”. A battery chemistry that looks fantastic on paper but cannot be manufactured at yield is a dead end. A grid technology that performs but cannot be permitted is a science project.
Then qθ. That is your proposal engine, the process that generates ideas. It might be an engineer’s intuition, a lab playbook, a simulation and optimisation loop, or an AI model proposing candidates. θ is whatever you can tune about that generator: training data, heuristics, prompts, priors, constraints, and the search strategy itself. The notation x ∼ qθ just means your candidates are being produced by that engine.
Finally c(x). That is the cost to evaluate x, or the cost to find out. Money, time, compute, lab runs, prototyping cycles, manufacturing time, regulatory effort. Some designs are cheap to test. Some are brutally expensive. Innovation is the game of finding high value x while spending as little c(x) as possible, and doing it repeatedly enough that the loop learns.
Two other bits of notation are worth just spelling out.
E_{x ∼ qθ}[·] just means “take the average over lots of ideas your generator produces”. You do not generate one idea. You generate many. This is the maths way of asking: on average, how good are my proposals, per cost to test?
arg max_θ means “choose the settings θ that make that average as large as possible”. In normal language: tune your idea generation process so it reliably produces ideas with high upside that are cheap to test. θ* is simply the best settings you end up with, the best tuned version of your proposal engine.
And this is how the equation captures the regime shift.
If c(x) falls a lot, then f(x)/c(x) rises a lot, even if f(x) does not change. When it becomes cheap to find out, you can run the loop more times, learn faster, and search more aggressively. I think of the old world like being a cautious sniper: few shots, lots of deliberation, heavy upfront planning. In the new world, it’s more like a search engine: many shots, tight feedback loops, rapid iteration.
Critically, c(x) is collapsing across multiple dimensions at once. Once c(x) falls far enough, the optimal strategy flips.
That flip is the activation energy drop. It is why matter and heavy industries look much more tractable than they did before.
Now the interesting part is why both halves of the loop are improving at the same time.
Why proposals get better and evaluation gets cheaper
Both sides of the loop are improving at the same time, but for different reasons. Proposal improves when qθ wastes fewer samples and lands closer to feasible, high value regions. Evaluation cheapens when c(x) falls, so you can run the loop more times and close it faster. The interesting part is the compounding: cheaper evaluation generates more feedback, feedback improves the generator, better generators waste fewer tests, and the cost of learning drops again.
On the proposal side, the first shift is better priors. In design spaces like proteins, crystals, catalysts, or process flows, random sampling is a waste of time and effort. Modern models and workflows start closer to “good” because they have internalised a lot of the structure of the domain. In biology, complex modelling of proteins has moved beyond single chain folding into richer interaction settings, including proteins with nucleic acids and small molecules. In chemistry, generative models increasingly produce valid molecules and plausible reaction pathways rather than strings that merely look chemical. In materials, foundation style atomistic models and structure aware generative systems encode symmetry, stability cues, and plausible coordination environments, which cuts down the number of dead on arrival candidates.
The second shift is that constraints are being built-in. The old workflow was to generate broadly, then filter hard, and in turn discover that most of what you generated violates stability, manufacturability, safety, or regulatory reality. The new workflow is to generate inside the box. In practice, that means conditioning the generator on target properties, enforcing constraints during sampling, or learning the boundary of feasibility and sampling from within it. Rather than asking “what already exists that sort of works?”, you ask “generate designs that meet these requirements”, and you get far fewer dead ends. The most important change is not that the model is “creative”, it is that it is less wasteful.
Third, feedback turns guessing into learning. The fastest path to better θ is a closed loop: propose, evaluate, update, propose again. That loop used to be slow because evaluation was slow. Now it is accelerating. Active learning pipelines in materials discovery are a good example: propose a batch of candidates, run a mixture of fast computational screening and selective high fidelity calculations, update the surrogate model, propose again. The same structure is showing up in wet lab settings, where automated platforms can run many small experiments and feed structured outcomes back into the next round of proposals. Once you can afford the loop, your proposal engine is no longer a one off brainstorm. It becomes a system that learns its way towards the feasible high value region.
Fourth, composability matters. High value designs are rarely conjured from nothing. They are assembled from motifs, modules and patterns that already work. In chemistry, this looks like recombining known fragments and scaffolds while respecting synthesizability. In manufacturing, it looks like recombining process modules and control policies rather than redesigning a factory from scratch. In power electronics, it looks like topology families and reusable subcircuits. Proposal engines get better when they can represent and recombine these building blocks, producing novelty without degenerating into nonsense.
Fifth, multi-objective thinking is becoming native. The real world does not reward “maximise one metric”. It rewards designs that survive the full multiplication in f(x). When proposal engines can target multiple objectives at once, you stop generating impressive single metric optimisations and start generating candidates that survive real world trade offs. In practice, this often means learning joint distributions rather than single property predictors, and using constrained optimisation rather than unconstrained search. It also means being honest about what you can evaluate cheaply versus what you must defer to expensive tests, and shaping the generator around that reality.
On the evaluation side, the first driver is that more evaluation moves from atoms to bits. The cheapest experiment is the one you never run. The new pattern is a layered evaluation stack: fast computational filters first, then higher fidelity simulation, then selective physical validation. Learned surrogates, neural operators, and foundation models for atomistic systems are increasingly used as ranking functions, not as final arbiters. They do not need to be perfect. They just need to be predictive enough to triage. If you can cheaply eliminate 90% of candidates before touching the lab or the line, c(x) collapses in an important way: you stop paying real world costs for obviously bad ideas.
A close cousin is differentiable simulation. Most simulation tells you “if I try x, this is what happens”. Differentiable simulation also tells you “if I nudge x a little in this direction, the outcome improves, and if I nudge it in that direction, it gets worse”. That matters because it turns search from trial and error into guided improvement. You can start from a plausible design, run the simulator, use the directional signal to adjust the design, and repeat. You still validate in the real world, but you arrive there with candidates that have already been pushed towards better performance, lower cost, or easier deployment, rather than burning experiments on obviously weak options.
The second driver is automation turning serial testing into parallel testing. The cost collapse is not only “each experiment is cheaper”. It is that the overhead per experiment falls and throughput rises. Automated synthesis platforms, robotic liquid handling, autonomous microscopy, and mobile robotics for laboratory operations all push in the same direction: the lab becomes a continuous system rather than a set of meetings on a calendar. In manufacturing, automation is doing the same job, turning iteration cycles into something closer to software deployment: instrument, measure, adjust, repeat. When the system can run overnight and weekends, the effective c(x) per unit of learning drops sharply.
Third, measurement is being commoditised, and interpretation is being automated. A large fraction of evaluation cost historically lived in “getting the data out” and “having an expert interpret it”. As sensors get cheaper and more ubiquitous, and as analysis becomes software, you get faster answers to “did it work?”, fewer ambiguous results, fewer reruns, and tighter feedback. This is unglamorous, but it is one of the most powerful ways c(x) falls, because it attacks delay and uncertainty.
Fourth, standardisation and reproducibility reduce hidden costs. The cost of evaluation is often in the chaos around it: inconsistent protocols, missing metadata, irreproducible setups, manual handoffs, poor traceability. As labs and factories become more software-like, with versioned protocols, automated logging, better provenance, and structured data capture, you reduce reruns, debugging time, compliance overhead, and tech transfer friction.
Fifth, compute is becoming dramatically cheaper and more capable, and that makes more of the loop software. Models can do more of the early evaluation, optimisation can run for longer, control systems can be more adaptive, and data can be processed and interpreted in near real time. In practice this turns evaluation into a hybrid workflow: models decide what to test, robots or operators execute, sensors measure, and software interprets and feeds the results back into the next round. The practical outcome is that the cost of “thinking” about a candidate falls, so you spend real world time and money only where it is most informative.
Sixth, in regulated domains, evaluation includes proving that something is safe, consistent, and traceable. A lot of cost comes from assembling evidence after the fact. Better instrumentation, logging and standard test routines can produce audit trails, provenance, and continuous monitoring as part of the workflow. That does not remove regulation, but it can reduce the marginal cost of satisfying it, and it can shorten the time between learning and deployability, which is a core component of f(x).
Put together, the loop changes character. Cheaper evaluation lets you test more candidates. More tests generate more data. More data improves qθ. Better qθ increases the fraction of candidates worth evaluating. Less waste frees budget and time for more tests. The funnel widens and the loop tightens. That is why things feel exponential: not because one curve is magical, but because multiple compounding improvements are hitting their useful region at the same time.
Why this matters for deep tech investing
If innovation is increasingly a search process, the investable edge shifts. The winners are not only teams with a single brilliant idea, but teams building the search machine: tight propose test learn loops, strong priors, and a credible path to cheap, scalable evaluation. When the time to learn compresses (see previous blog on this linked below), the time to generate real technical signal compresses too. That changes diligence because you can underwrite teams on learning rate and evidence produced, not just on a narrative. It changes portfolio construction because cycles shorten, follow-on decisions are more likely to be made earlier with better information, and the gap between “promising” and “proven” reduces. And it changes what early proof looks like because a working loop and credible iteration speed can matter as much as a single headline milestone.
This is the practical consequence of the activation energy drop. When c(x) collapses and qθ improves, deep tech feels more tractable because progress is no longer gated by a handful of expensive, slow, bespoke experiments. You can afford more shots and you can afford to be wrong more often, because being wrong is cheaper and faster. That turns domains that used to reward caution into domains that reward throughput and learning.
Matter industries are clearly the new frontier. The difference is that they are becoming more tractable, because more of the uncertainty can be cleared earlier and more cheaply, and because iteration can happen at a cadence that used to be impossible outside of software. They have always been constrained by the cost of touching atoms: long iteration cycles, high capex, and uncertainty that only clears once you build the thing. As more of that uncertainty is cleared earlier through better simulation, surrogate models, automation, and high cadence measurement, the search moves upstream. You can explore more of the design space before you pour concrete, you can converge on manufacturable process windows before you scale, and you can de-risk integration and reliability with far more repetitions than was previously economical. Once “find out” is cheap enough, the limiting factor becomes the quality of your loop, not the size of your budget.
Vertical integration also makes more sense in this regime because the loop is the asset. The highest leverage learning comes from owning the interfaces between design, testing, manufacturing and deployment, and from keeping the data and feedback inside one system. When you outsource key parts of the loop, you lose iteration speed, you lose observability, and you lose the ability to compound learnings across stages. In matter heavy businesses, integration is also where the constraints hide: yield, supply chain, reliability, certification, installation, servicing. A vertically integrated company can treat those constraints as first class inputs to qθ, not downstream surprises, and can drive c(x) down by standardising workflows and running far more cycles through the same stack. In a world where advantage comes from learning rate, ownership of the end to end loop is often the moat.
In sum, when activation energy drops, the cost to find out falls and the quality of proposals rises, so innovation turns into compounding iteration, and that is a real unlock for matter industries.
Thanks for reading - please share and comment!
It sounds like you're proposing something along the lines of a Moore's law for AI in discovery